module03
速答
Q: 单细胞质控过滤线粒体比例阈值多少?
A: 通常 10-15%,PBMC 用 10%,组织样本可放宽到 20%。Seurat 用 PercentageFeatureSet(object, pattern = "^MT-") 计算。
Q: Seurat 标准化用 LogNormalize 还是 SCTransform?
A: 入门用 LogNormalize(NormalizeData() 默认),稳定好理解。SCTransform 更先进但参数复杂,适合多样本整合时用。
Q: 聚类 resolution 怎么选? A: PBMC 3k 用 0.4-0.6,能分出主要免疫亚群。细胞数多(>10k)可到 0.8-1.2。看 UMAP 上 cluster 是否过度切碎,太碎就调低。
Q: 选多少个 PC 做聚类?
A: 用 ElbowPlot() 看拐点,通常 10-30。PBMC 3k 一般用 10-15。太多引入噪声,太少丢信号。
Q: FindMarkers 和 bulk 的 DESeq2 有什么区别? A: FindMarkers 用 Wilcoxon / MAST,适合单细胞稀疏数据;DESeq2 用负二项模型,适合 bulk。单细胞差异分析推荐 Wilcoxon(默认)或 MAST。
03 质量控制、聚类与细胞类型注释
拿到 Cell Ranger(或同类工具)输出的表达矩阵,接下来要做的事情大致是一条固定的流水线:过滤掉质量差的细胞和基因、把深度差异归一化掉、挑选有信息量的基因、降维、聚类、给每个 cluster 贴上细胞类型标签、找差异基因。这条流�水线是所有下游分析(整合、轨迹、通讯等)的起点,走通一次之后,后面所有模块都基于它继续。
本节以 Seurat 为主线走一遍这条流程,同时给出 Scanpy 的等价写法。数据用 01 章里介绍的 PBMC 3k 公开数据,跑完之后你会得到一张 UMAP 图,上面的每个细胞都被标了 CD4 T、CD8 T、B、NK、monocyte 等注释。
为什么这条流水线不能跳步
每一步都是为了去掉一种已知的干扰,让最后看到的 cluster 反映真实的生物学差异,而不是技术噪声:
| 步骤 | 不做会怎样 |
|---|---|
| QC 过滤 | 死细胞 / 双细胞混在数据里,后面所有 cluster 都被它们污染 |
| 标准化 | 测序深度高的细胞看上去"什么基因都表达",假装成一个独立 cluster |
| 高变基因 | 两万个基因里大多数�是恒定的"持家基因",会稀释真正区分细胞的信号 |
| 缩放 | PCA 被高表达基因(线粒体、核糖体)主导,主成分变成"细胞活性"而不是"细胞类型" |
| PCA | 直接在两千维上跑聚类,又慢又被噪声带偏 |
| 选 PC 数 | 用太多 PC → 噪声进入;用太少 → 信号被丢 |
记住这条:"每一步都是在去掉一种伪信号",比死记步骤名字管用得多。
流程概览
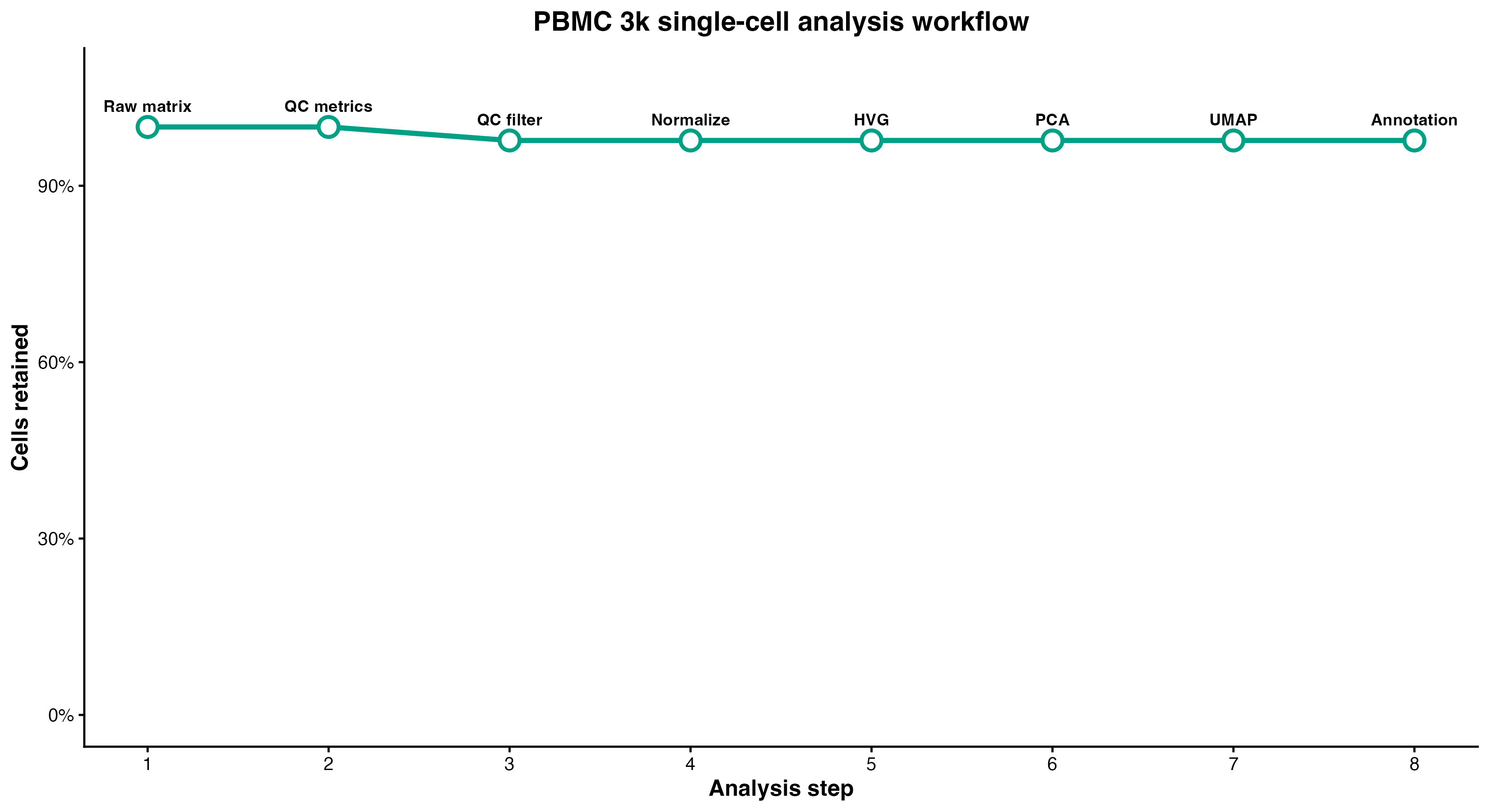
图 1:单细胞分析完整流程。展示了从原始数据到细胞类型注释的 8 个主要步骤及细胞保留率。
表达矩阵
↓ 质控:按基因数、UMI 数、线粒体比例过滤细胞
↓ 标准化:消除测序深度差异(LogNormalize 或 SCTransform)
↓ 高变基因:选最有信息量的 ~2000 个基因
↓ 缩放:把这些基因归一化到均值 0 方差 1
↓ PCA:把 2000 维降到 ~30 维
↓ 邻居图 + 聚类:找到 cluster
↓ UMAP:把 ~30 维压成 2D 可视化
↓ 差异基因:每个 cluster vs 其他的 marker
↓ 细胞类型注释:marker 对照或 SingleR 自动
环境准备
只需要跑一次:
install.packages(c("Seurat", "dplyr", "ggplot2"))
if (!require("BiocManager", quietly = TRUE)) install.packages("BiocManager")
BiocManager::install(c("SingleR", "celldex", "clusterProfiler"))
Python 端:
pip install scanpy python-igraph leidenalg
读入数据
假设 filtered_feature_bc_matrix/ 已经存在(01 章和 02 章的产物)。
library(Seurat)
library(dplyr)
library(ggplot2)
data <- Read10X(data.dir = "path/to/filtered_feature_bc_matrix/")
pbmc <- CreateSeuratObject(
counts = data,
project = "PBMC3k",
min.cells = 3, # 基因至少在 3 个细胞里表达
min.features = 200 # 细胞至少检测到 200 个基因
)
pbmc
Scanpy 的等价写法:
import scanpy as sc
adata = sc.read_10x_mtx("path/to/filtered_feature_bc_matrix/", var_names="gene_symbols")
sc.pp.filter_cells(adata, min_genes=200)
sc.pp.filter_genes(adata, min_cells=3)
Seurat 的 min.cells 和 min.features 是"创建对象时就先丢一批明显垃圾的 barcode 和 gene",不用来做最终的 QC 过滤。
质量控制
最常看的三项 QC 指标:
| 指标 | Seurat 字段 | Scanpy 字段 | 合理范围 | 异常提示 |
|---|---|---|---|---|
| 每细胞基因数 | nFeature_RNA | n_genes_by_counts | 200 – 6,000 | 过低 → 空液滴/破损;过高 → 双细胞 |
| 每细胞 UMI 数 | nCount_RNA | total_counts | 500 – 50,000 | 过低 → 测序不足;过高 → 双细胞 |
| 线粒体基因比例 | percent.mt | pct_counts_mt | < 5 – 10% | 过高 → 细胞破损 / 应激 |
具体阈值要看这份数据自己的分布,不是死背上面的数字。一般做法是先算指标 → 画小提琴图看分布 → 按分布定阈值。
计算指标
pbmc[["percent.mt"]] <- PercentageFeatureSet(pbmc, pattern = "^MT-")
# 可选:核糖体蛋白基因也常用
pbmc[["percent.rb"]] <- PercentageFeatureSet(pbmc, pattern = "^RP[SL]")
head(pbmc@meta.data)
adata.var["mt"] = adata.var_names.str.startswith("MT-")
sc.pp.calculate_qc_metrics(
adata, qc_vars=["mt"], percent_top=None, log1p=False, inplace=True,
)
看分布
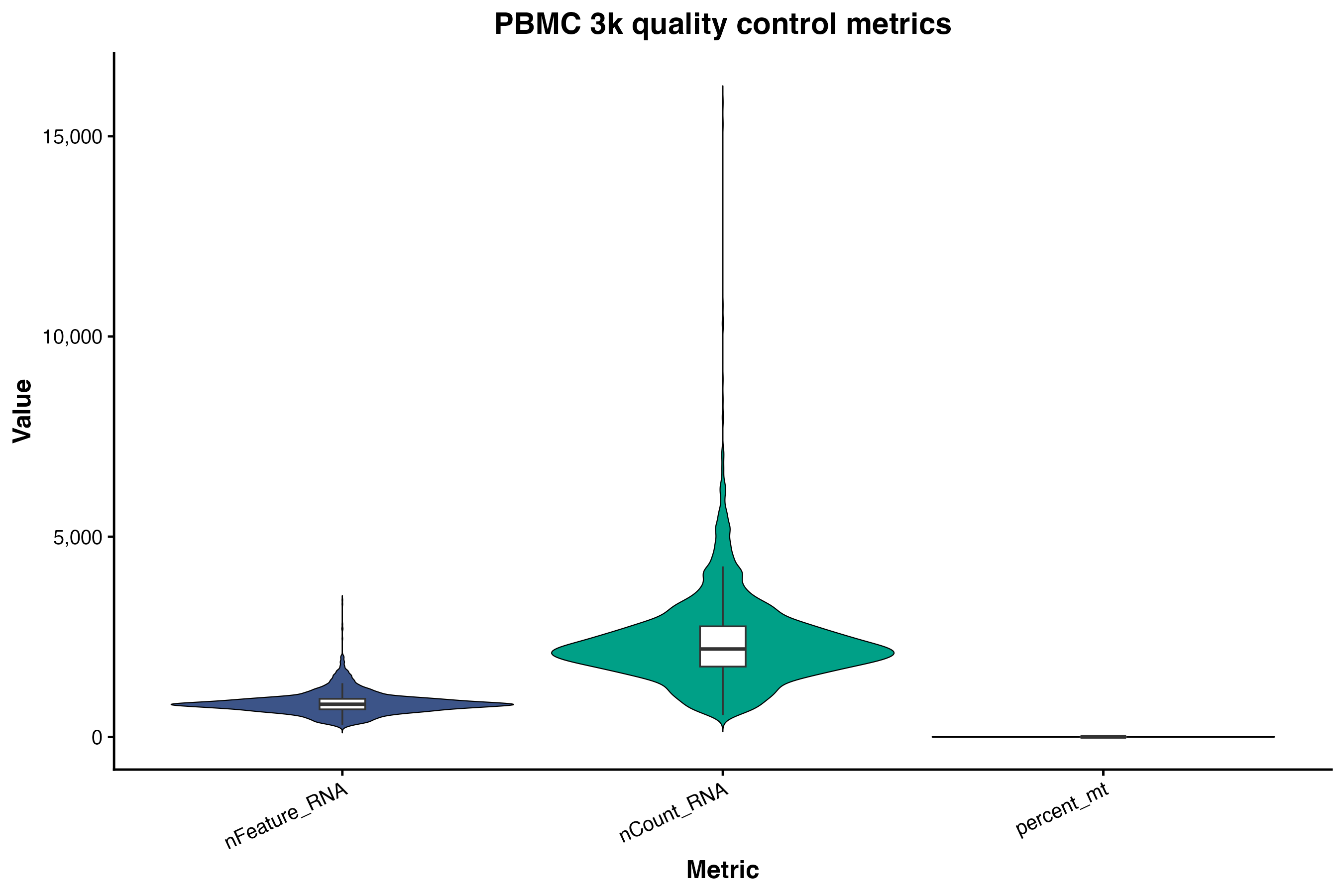
图 2:质量控制指标小提琴图。展示了基因数、UMI 数和线粒体基因比例的分布情况。
VlnPlot(pbmc, features = c("nFeature_RNA", "nCount_RNA", "percent.mt"), ncol = 3)
# 两两散点:UMI vs 线粒体、UMI vs 基因数
FeatureScatter(pbmc, feature1 = "nCount_RNA", feature2 = "percent.mt") +
FeatureScatter(pbmc, feature1 = "nCount_RNA", feature2 = "nFeature_RNA")
散点图比小提琴更有用:两个尖峰不代表双模态,但右上角偏离主分布的点通常是双细胞。
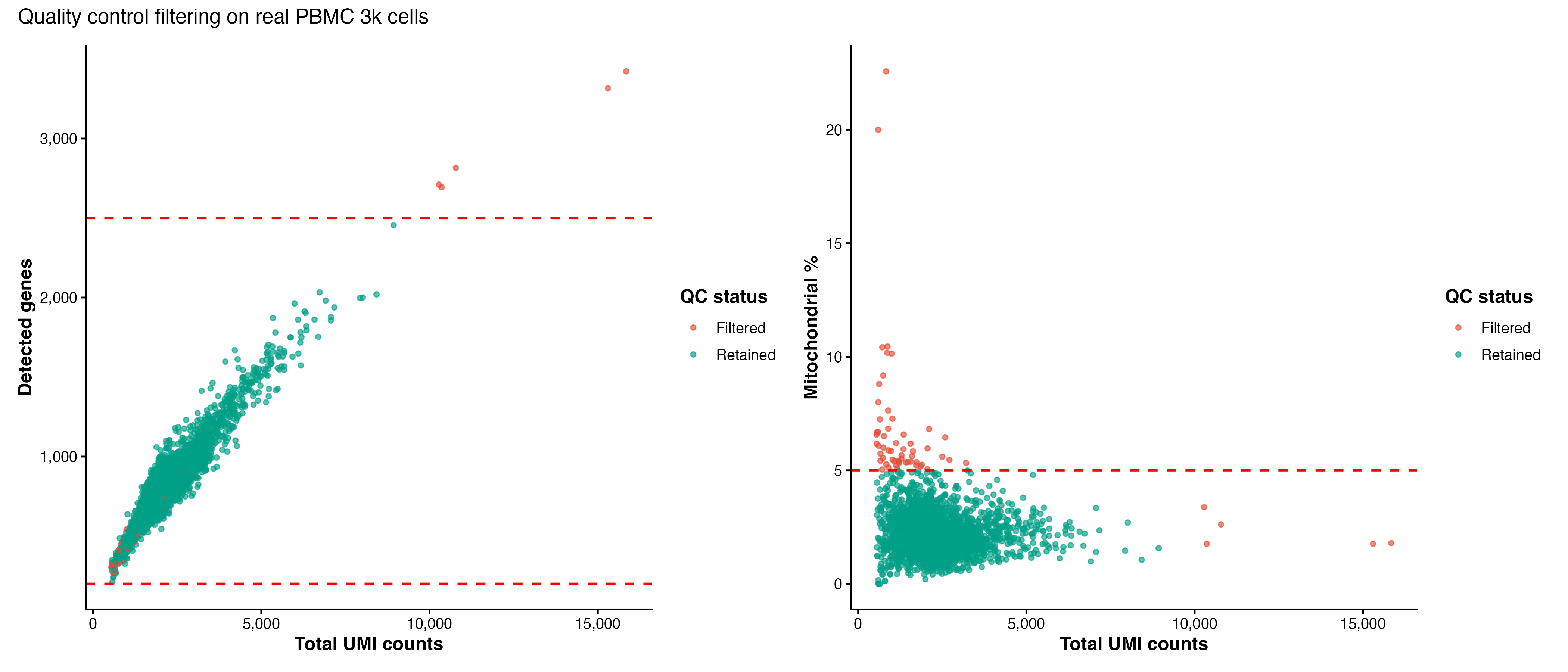
图 3:质量控制过滤散点图。左图展示 UMI 数与基因数的关系,右图展示 UMI 数与线粒体基因比例的关系。红色虚线表示过滤阈值,绿色点为保留的细胞,红色点为过滤的细胞。
过滤
pbmc <- subset(pbmc,
subset = nFeature_RNA > 200 & nFeature_RNA < 2500 & percent.mt < 5
)
pbmc
sc.pp.filter_cells(adata, max_genes=2500)
adata = adata[adata.obs.pct_counts_mt < 5, :]
标准化
不同细胞的测序深度差距能有十倍以上。直接比较 raw counts 会把"深度不同"当成"生物学差异"。标准化的目标是让每个细胞的表达量在同一刻度上。
最常见有两种选择:
- LogNormalize:每个细胞归一化到相同总 UMI(默认 10000),再
log1p。快、适合教学。 - SCTransform:负二项回归建模,同时归一化和去除技术协变量。效果更好,但慢。
PBMC 教学数据用 LogNormalize 就够;真实项目里 SCTransform 更稳。
为什么要 log1p:基因表达的差异是乘法的(A 比 B 多 10 倍 vs 多 100 倍),不是加法的。log 变换把乘法差距压成加法差距,下游 PCA 这种线性方法才能用。log1p(即 log(x+1))是为了处理 x=0 的情况(log(0) 是负无穷)。
为什么不用 RPKM/TPM:scRNA-seq 的 UMI 已经去掉了 PCR duplicate,不需要按"基因长度"归一化(每个基��因每次只测到一个 UMI 就计 1)。RPKM/TPM 是 bulk RNA-seq 的概念,单细胞用 LogNormalize 或 SCTransform 即可。
# LogNormalize 路线
pbmc <- NormalizeData(pbmc, normalization.method = "LogNormalize", scale.factor = 10000)
# 或 SCTransform 路线(可选替代,如果用这个就跳过后面的 ScaleData)
# pbmc <- SCTransform(pbmc, vars.to.regress = "percent.mt", verbose = FALSE)
sc.pp.normalize_total(adata, target_sum=1e4)
sc.pp.log1p(adata)
adata.raw = adata # 后面做 FindMarkers 时用得到原始归一化数据
特征选择:找高变基因
一个矩阵有两万多个基因,但大多数基因在所有细胞里都差不多。聚类前先筛出 ~2000 个"在细胞间差异最大"的基因(highly variable genes),既减少计算量又降低技术噪声影响。
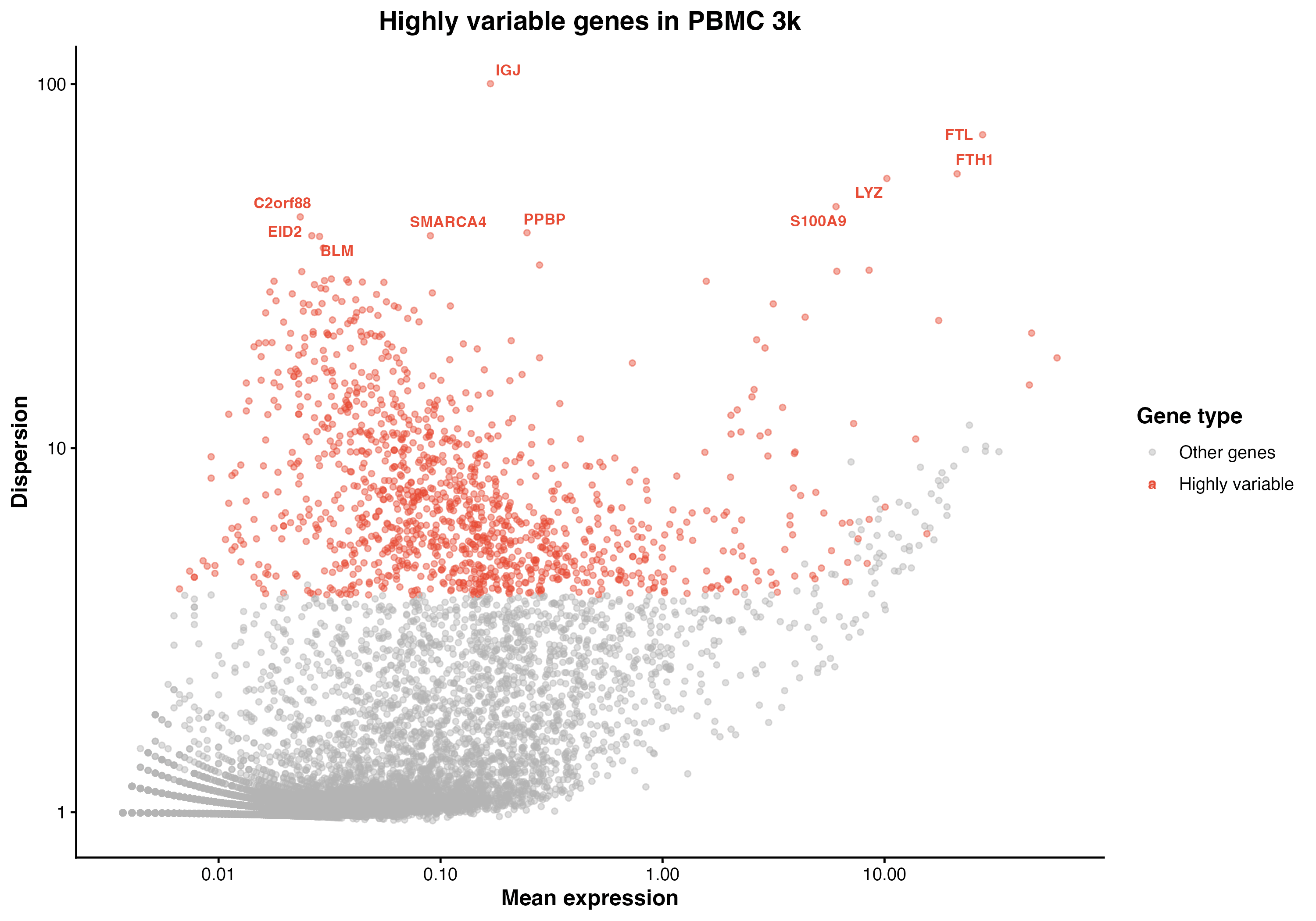
图 4:高变异基因选择。展示了基因的平均表达量与离散度的关系,红色点为高变异基因,标注了前 10 个高变异基因。
pbmc <- FindVariableFeatures(pbmc, selection.method = "vst", nfeatures = 2000)
top10 <- head(VariableFeatures(pbmc), 10)
LabelPoints(plot = VariableFeaturePlot(pbmc), points = top10, repel = TRUE)
sc.pp.highly_variable_genes(adata, min_mean=0.0125, max_mean=3, min_disp=0.5)
sc.pl.highly_variable_genes(adata)
adata = adata[:, adata.var.highly_variable]
缩放
PCA 前把每个基因归一化到均值 0 方差 1,避免高表达基因主导主成分。vars.to.regress 可以在这一步同时把线粒体比例、UMI 数等协变量 regress out:
pbmc <- ScaleData(pbmc) # 默认只缩放高变基因
sc.pp.regress_out(adata, ["total_counts", "pct_counts_mt"])
sc.pp.scale(adata, max_value=10)
PCA 降维
pbmc <- RunPCA(pbmc, features = VariableFeatures(pbmc), npcs = 50)
# 打印前几个 PC 上 loading 最高的基因
print(pbmc[["pca"]], dims = 1:5, nfeatures = 5)
sc.tl.pca(adata, svd_solver="arpack")
选多少个 PC
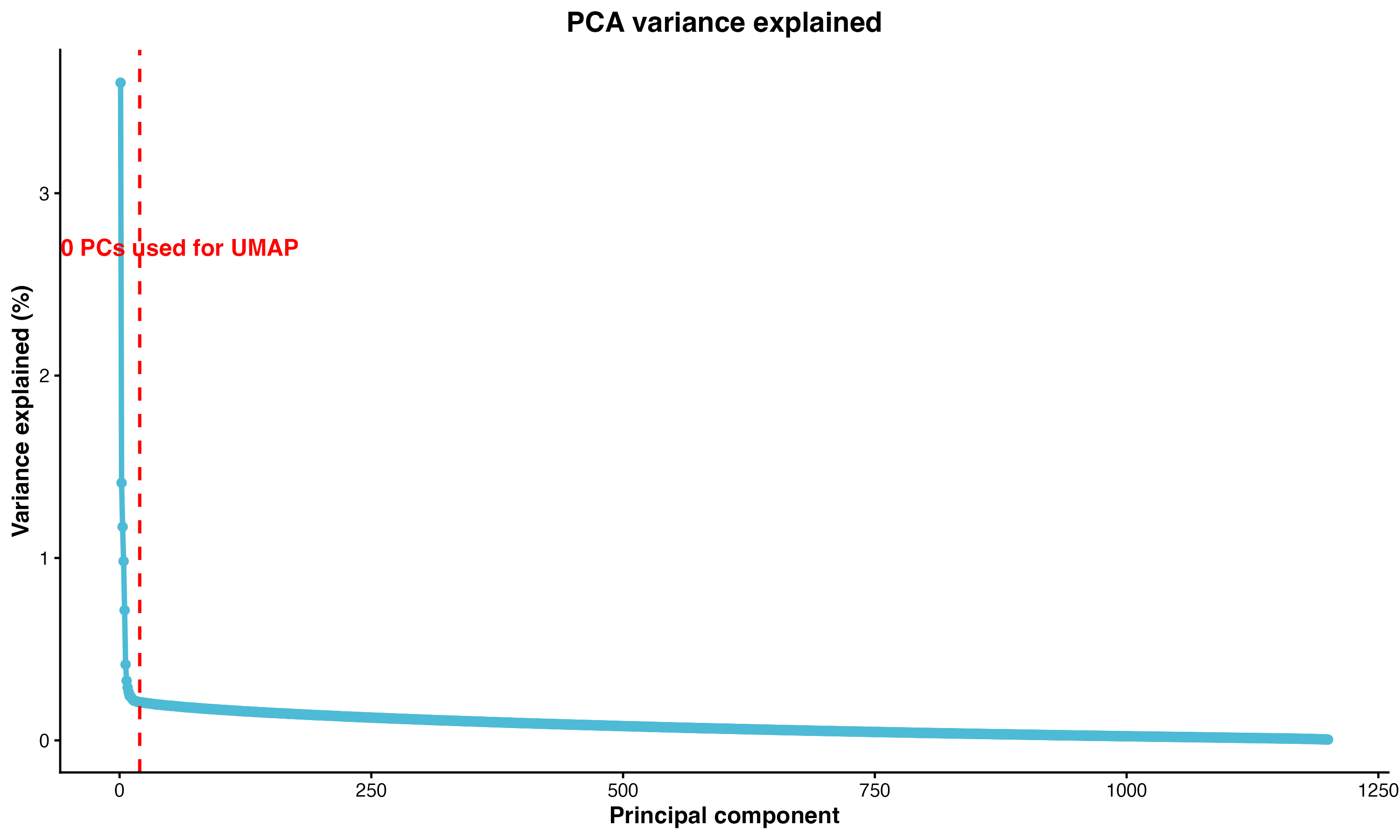
图 5:PCA 方差解释图(Elbow Plot)。展示了每个主成分解释的方差比例,红色虚线标注了选择的 PC 数量(20 个)。
看 elbow plot:方差解释率下降突然变平的位置,就是合理的 PC 数。PBMC 通常选 10-30,不用纠结具体选 15 还是 20,结果差别不大。
ElbowPlot(pbmc, ndims = 50)
sc.pl.pca_variance_ratio(adata, n_pcs=50)
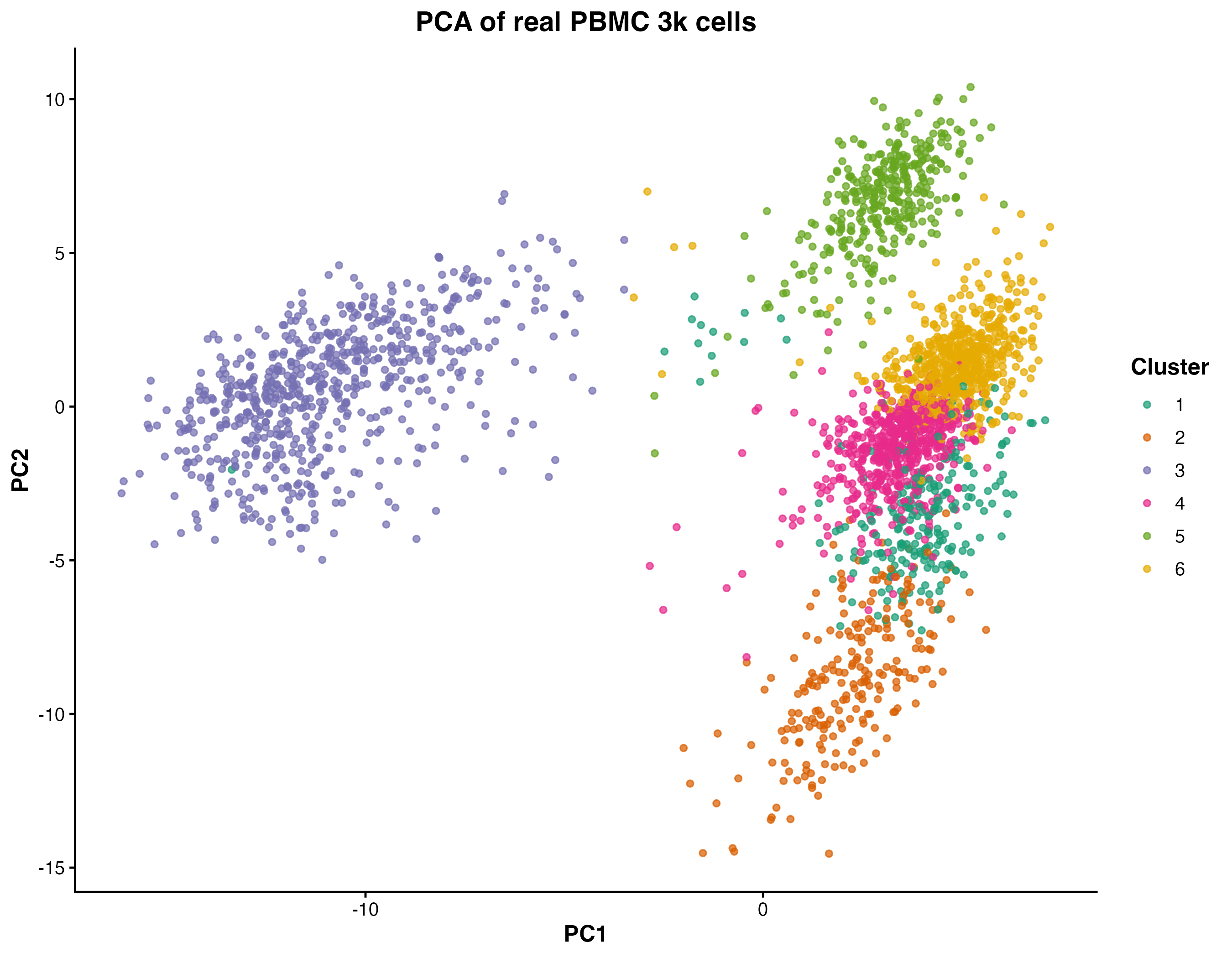
图 6:PCA 散点图。展示了前两个主成分(PC1 和 PC2)的细胞分布,不同颜色代表不同的聚类。
聚类
用选好的 PC 构建 KNN 图,再在图上做 Louvain/Leiden 聚类。resolution 是唯一要调的参数:值越大 cluster 越多。
pbmc <- FindNeighbors(pbmc, dims = 1:20)
pbmc <- FindClusters(pbmc, resolution = 0.5)
sc.pp.neighbors(adata, n_neighbors=10, n_pcs=40)
sc.tl.leiden(adata, resolution=0.5)
resolution 没有绝对正确值。一般从 0.5 开始,结合后面 marker gene 的合理性和生物学预期微调。PBMC 3k 在 resolution=0.5 下通常分出 8-9 个 cluster,对应主要免疫细胞类型。
UMAP 可视化
UMAP 本身不影响聚类结果(聚类是在 PC 空间做的),只是把高维结构投影到 2D 方便人看。
UMAP 是单细胞数据最常见的二维可视化。下面这张 figcode 卡片可以直接在线绘图,把你自己的 Seurat 对象画成同样的样式。
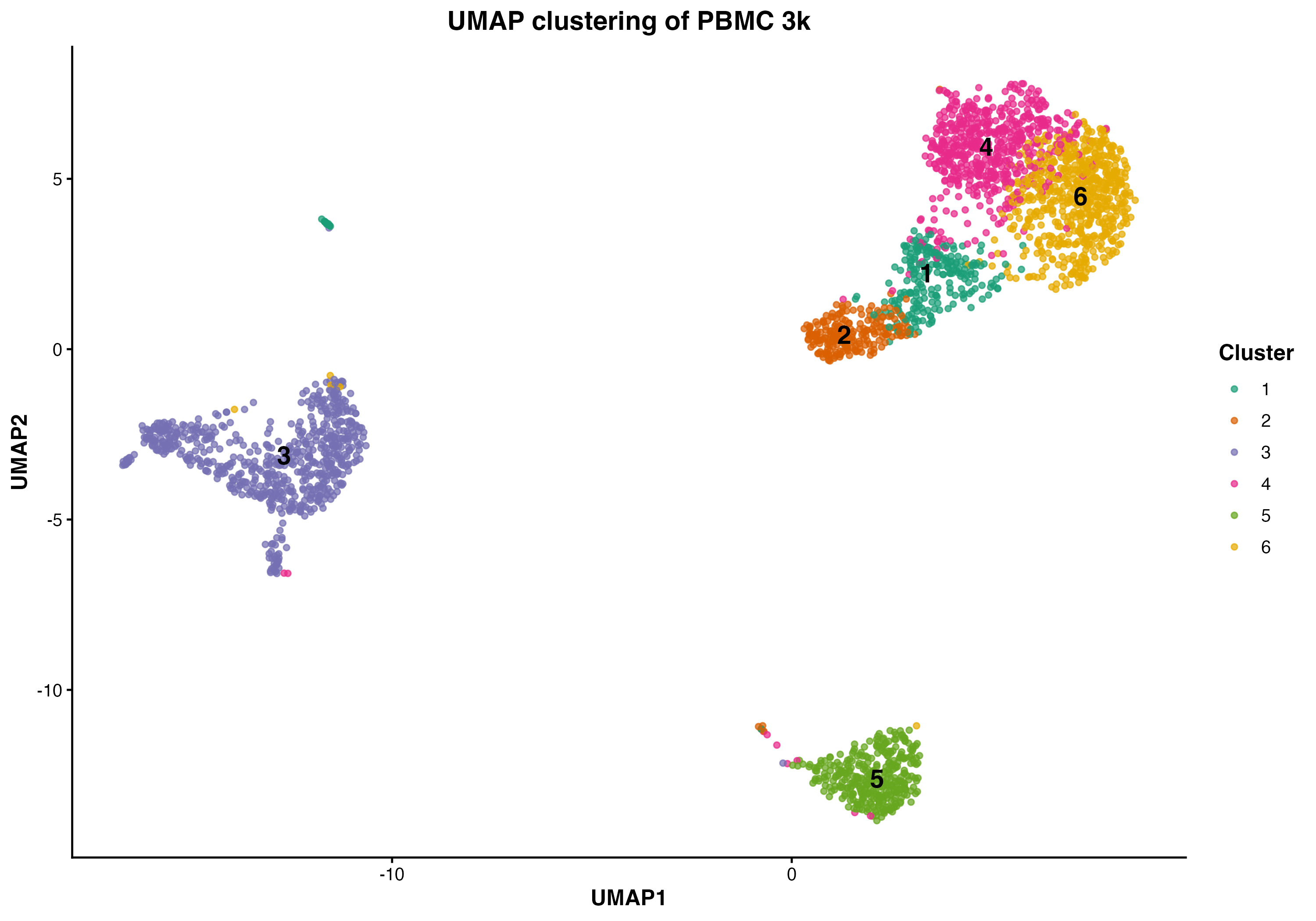
图 7:UMAP 聚类可视化。展示了 6 个细胞簇在 UMAP 空间中的分布,数字标注了簇的编号。
pbmc <- RunUMAP(pbmc, dims = 1:20)
DimPlot(pbmc, reduction = "umap", label = TRUE)
# 用 marker 基因上色验证聚类
FeaturePlot(pbmc, features = c("MS4A1", "CD79A", "CD3D", "CD8A"))
sc.tl.umap(adata)
sc.pl.umap(adata, color=["leiden", "CST3", "NKG7"])
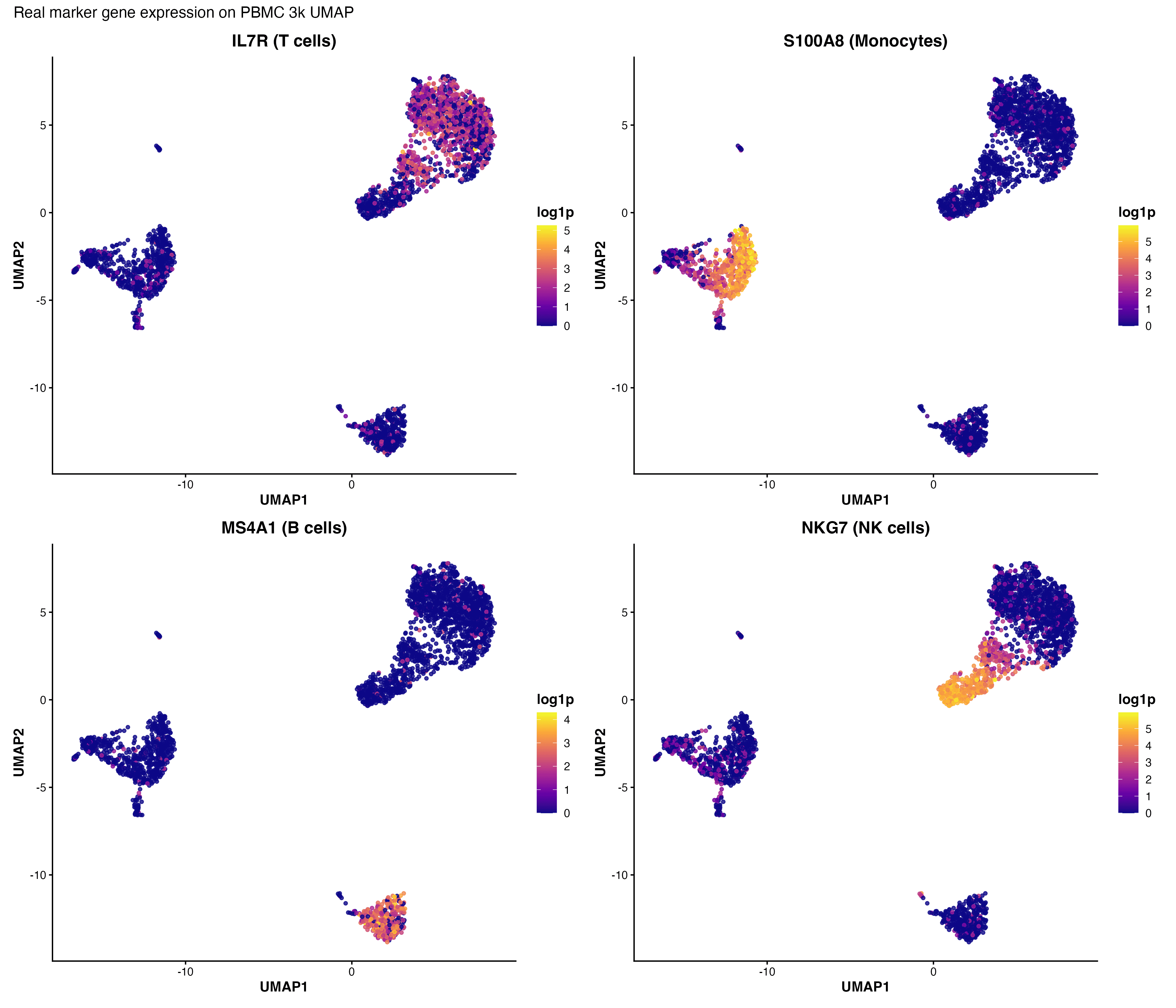
图 8:UMAP 上的标志基因表达。展示了 CD3D(T 细胞)、CD14(单核细胞)、MS4A1(B 细胞)和 NKG7(NK 细胞)的表达模式。
把 UMAP 染上聚类编号,再把几个已知 marker 画在同样的坐标上——如果 CD3D 的高表达区域恰好覆盖某个 cluster,这就是该 cluster 是 T 细胞的证据。
找 marker 基因
每个 cluster 和"其他 cluster 总和"做差异表达,就能得到这个 cluster 的 marker:
pbmc.markers <- FindAllMarkers(
pbmc,
only.pos = TRUE,
min.pct = 0.25,
logfc.threshold = 0.25
)
# 每个 cluster 前 5 个 marker
pbmc.markers %>% group_by(cluster) %>% slice_max(n = 5, order_by = avg_log2FC)
sc.tl.rank_genes_groups(adata, "leiden", method="wilcoxon")
sc.pl.rank_genes_groups(adata, n_genes=25, sharey=False)
热图把 top marker 画在一起看:
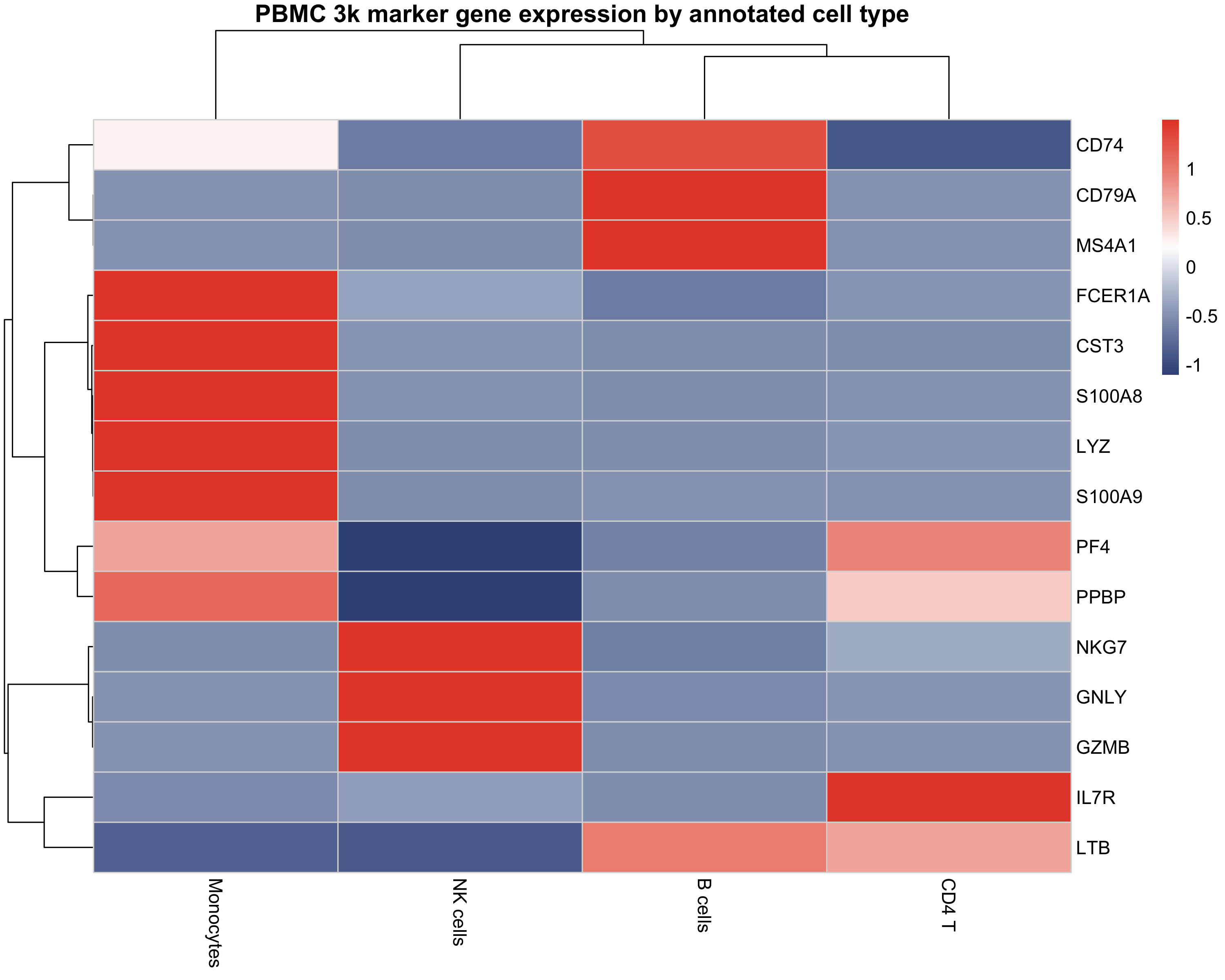
图 9:标志基因表达热图。展示了不同细胞类型的特征标志基因表达模式,每列代表一个细胞簇。
top10 <- pbmc.markers %>% group_by(cluster) %>% top_n(10, avg_log2FC)
DoHeatmap(pbmc, features = top10$gene) + NoLegend()
细胞类型注释
手动:按经典 marker 对照
PBMC 里常用的一组 marker:
| 细胞类型 | 经典 marker |
|---|---|
| CD4+ T | IL7R, CD4, CCR7(naive)/S100A4(memory) |
| CD8+ T | CD8A, CD8B |
| B | MS4A1 (CD20), CD79A |
| NK | GNLY, NKG7 |
| 单核 CD14 | CD14, LYZ |
| 单核 FCGR3A | FCGR3A, MS4A7 |
| 树突 | FCER1A, CST3 |
| 巨核 / 血小板 | PPBP |
对照 cluster 的 top marker 决定怎么命名:
new_ids <- c(
"Naive CD4 T", "CD14+ Mono", "Memory CD4 T", "B",
"CD8 T", "FCGR3A+ Mono", "NK", "DC", "Platelet"
)
names(new_ids) <- levels(pbmc)
pbmc <- RenameIdents(pbmc, new_ids)
DimPlot(pbmc, reduction = "umap", label = TRUE, pt.size = 0.5) + NoLegend()
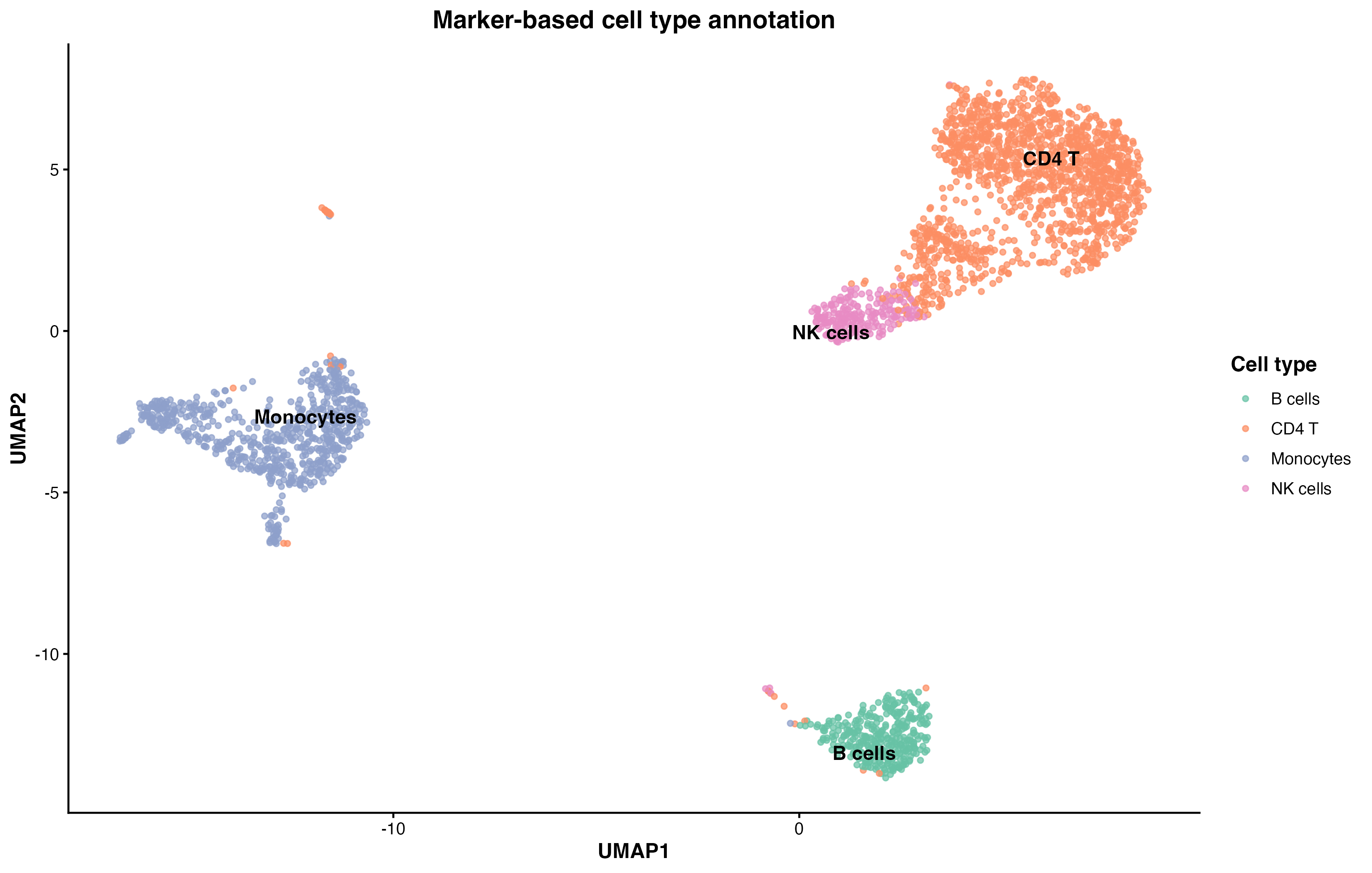
图 10:细胞类型注释 UMAP 图。展示了 6 种主要细胞类型在 UMAP 空间中的分布。
自动:SingleR
SingleR 拿一份参考数据集做最近邻注释,适合快速拿个初稿:
library(SingleR)
library(celldex)
ref <- celldex::HumanPrimaryCellAtlasData()
sce <- as.SingleCellExperiment(pbmc)
pred <- SingleR(test = sce, ref = ref, labels = ref$label.main)
pbmc$singler <- pred$labels
DimPlot(pbmc, reduction = "umap", group.by = "singler")
自动注释适合做第一轮筛查,但最终 cluster 命名还是得回到 marker gene + 人工判断。
差异�表达:两组比较
注释之后,常见需求是对两群细胞做差异分析(比如 CD4 T vs CD8 T):
cd4_vs_cd8 <- FindMarkers(pbmc, ident.1 = "CD4 T", ident.2 = "CD8 T")
head(cd4_vs_cd8)
sc.tl.rank_genes_groups(
adata, "cell_type", groups=["CD4 T"], reference="CD8 T", method="wilcoxon"
)
sc.pl.rank_genes_groups(adata)
功能富集
把某个 cluster 的 marker 做 GO/KEGG 富集,看它主要落在什么通路:
library(clusterProfiler)
library(org.Hs.eg.db)
cluster0_genes <- pbmc.markers %>%
filter(cluster == 0, p_val_adj < 0.05) %>% pull(gene)
gene_ids <- bitr(cluster0_genes,
fromType = "SYMBOL", toType = "ENTREZID", OrgDb = org.Hs.eg.db
)
ego <- enrichGO(
gene = gene_ids$ENTREZID,
OrgDb = org.Hs.eg.db,
ont = "BP",
pAdjustMethod = "BH",
pvalueCutoff = 0.05
)
dotplot(ego, showCategory = 10)
kk <- enrichKEGG(gene = gene_ids$ENTREZID, organism = "hsa")
dotplot(kk, showCategory = 10)
保存结果
saveRDS(pbmc, "pbmc_analyzed.rds")
write.csv(pbmc@meta.data, "metadata.csv")
write.csv(pbmc.markers, "marker_genes.csv")
adata.write("pbmc_analyzed.h5ad")
分析脚本和输出一起提交到版本控制,下次复现或多样本整合时能直接用。
常见坑
坑 1:线粒体过滤阈值死搬 5%
percent.mt < 5% 是 PBMC 这种新鲜外周血样本的经验值。冷冻样本、肿瘤样本、肝脏 / 心肌等富线粒体组织,5% 会把好细胞全过滤掉。先看 VlnPlot(percent.mt) 的实际分布,找"主峰之外的尾巴"那个值做阈值,不是死背 5%。
坑 2:resolution 调高了出现 cluster 数膨胀
resolution 从 0.5 调到 1.5,cluster 从 9 个变成 25 个。多出来的 cluster 大多没有生物学意义,是把同一类细胞按内部状态(细胞周期、应激)切碎了。看下游 marker:如果两个 cluster 的 top 5 marker 高度重叠,说明被过分切了,调回去。
坑 3:FindAllMarkers 之后没改 DefaultAssay
如果用了 SCTransform 或后面有整合,DefaultAssay 可能是 SCT 或 integrated。在这上面跑 FindAllMarkers,得到的是变换后的"伪表达"差异。做差异分析前一定切回 DefaultAssay(pbmc) <- "RNA"。
坑 4:把"看上去能分开"当成"分对了"
UMAP 上分得再开,也只是说明这群细胞在高维空间里离得远。不等于细胞类型不同。一个 CD4 T cluster 可能因为细胞周期阶段不同被分成 G1 期和 S/G2/M 期两堆 — UMAP 上像两个不同细胞类型。看 marker 时同时看细胞周期得分(CellCycleScoring),能避免这种误判。
坑 5:手动注释只看 top1 marker
某个 cluster 的 top1 是 LYZ,就标 "Monocyte"。问题:LYZ 在 DC 里也高表达,IL7R 也是 — 单 marker 不够特异。至少看 top 5 marker 的组合 + 配合 FeaturePlot 在 UMAP 上确认这群细胞确实集中表达这些 marker。
下载资源
下一步
接着深入:
- 04 多样本数据整合 — 你现在能跑完单样本的全流程,下一步是把多个样本对齐到同一张 UMAP 上。这是真实项目(治疗 vs 对照、多个个体)必经的下一步。
横向延伸:
- 05 轨迹推断与拟时序分析 — 如果你的数据是分化 / 发育过程,UMAP 看到的 "cluster" 其实是连续路径上的几个点
- FigCode UMAP — 直接套你刚生成的 Seurat 对象出一张可发表的 UMAP
参考资源
离线资料下载
手册 HTML / PDF 已在后台预生成,点击后直接下载网站静态资源。